使用Embedding API
本文对应源代码在此处,如需复现可下载运行源代码。
一、使用OpenAI API
GPT有封装好的接口,我们简单封装即可。目前GPT embedding mode有三种,性能如下所示:
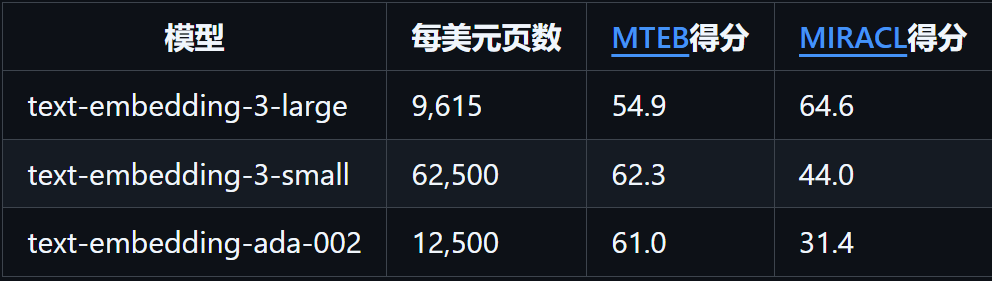
从以上三个embedding model我们可以看出text-embedding-3-large有最好的性能和最贵的价格,当我们搭建的应用需要更好的表现且成本充足的情况下可以使用;text-embedding-3-small有着较好的性能跟价格,当我们预算有限时可以选择该模型;而text-embedding-ada-002是OpenAI上一代的模型,无论在性能还是价格都不如及前两者,因此不推荐使用。
import osfrom openai import OpenAIfrom dotenv import load_dotenv, find_dotenv# 读取本地/项目的环境变量。# find_dotenv()寻找并定位.env文件的路径# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中# 如果你设置的是全局的环境变量,这行代码则没有任何作用。_ = load_dotenv(find_dotenv())# 如果你需要通过代理端口访问,你需要如下配置os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'def openai_embedding(text: str, model: str=None):# 获取环境变量 OPENAI_API_KEYapi_key=os.environ['OPENAI_API_KEY']client = OpenAI(api_key=api_key)# embedding model:'text-embedding-3-small', 'text-embedding-3-large', 'text-embedding-ada-002'if model == None:model="text-embedding-3-small"response = client.embeddings.create(input=text,model=model)return responseresponse = openai_embedding(text='要生成 embedding 的输入文本,字符串形式。')
API返回的数据为json格式,除object向量类型外还有存放数据的data、embedding model 型号model以及本次 token 使用情况usage等数据,具体如下所示:
{"object": "list","data": [{"object": "embedding","index": 0,"embedding": [-0.006929283495992422,... (省略)-4.547132266452536e-05,],}],"model": "text-embedding-3-small","usage": {"prompt_tokens": 5,"total_tokens": 5}}
我们可以调用response的object来获取embedding的类型。
print(f'返回的embedding类型为:{response.object}')
返回的embedding类型为:list
embedding存放在data中,我们可以查看embedding的长度及生成的embedding。
print(f'embedding长度为:{len(response.data[0].embedding)}')print(f'embedding(前10)为:{response.data[0].embedding[:10]}')
embedding长度为:1536embedding(前10)为:[0.03884002938866615, 0.013516489416360855, -0.0024250170681625605, -0.01655769906938076, 0.024130908772349358, -0.017382603138685226, 0.04206013306975365, 0.011498954147100449, -0.028245486319065094, -0.00674333656206727]
我们也可以查看此次embedding的模型及token使用情况。
print(f'本次embedding model为:{response.model}')print(f'本次token使用情况为:{response.usage}')
本次embedding model为:text-embedding-3-small本次token使用情况为:Usage(prompt_tokens=12, total_tokens=12)
二、使用文心千帆API
Embedding-V1是基于百度文心大模型技术的文本表示模型,Access token为调用接口的凭证,使用Embedding-V1时应先凭API Key、Secret Key获取Access token,再通过Access token调用接口来embedding text。同时千帆大模型平台还支持bge-large-zh等embedding model。
import requestsimport jsondef wenxin_embedding(text: str):# 获取环境变量 wenxin_api_key、wenxin_secret_keyapi_key = os.environ['QIANFAN_AK']secret_key = os.environ['QIANFAN_SK']# 使用API Key、Secret Key向https://aip.baidubce.com/oauth/2.0/token 获取Access tokenurl = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={0}&client_secret={1}".format(api_key, secret_key)payload = json.dumps("")headers = {'Content-Type': 'application/json','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)# 通过获取的Access token 来embedding texturl = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/embeddings/embedding-v1?access_token=" + str(response.json().get("access_token"))input = []input.append(text)payload = json.dumps({"input": input})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)return json.loads(response.text)# text应为List(string)text = "要生成 embedding 的输入文本,字符串形式。"response = wenxin_embedding(text=text)
Embedding-V1每次embedding除了有单独的id外,还有时间戳记录embedding的时间。
print('本次embedding id为:{}'.format(response['id']))print('本次embedding产生时间戳为:{}'.format(response['created']))
本次embedding id为:as-hvbgfuk29u本次embedding产生时间戳为:1711435238
同样的我们也可以从response中获取embedding的类型和embedding。
print('返回的embedding类型为:{}'.format(response['object']))print('embedding长度为:{}'.format(len(response['data'][0]['embedding'])))print('embedding(前10)为:{}'.format(response['data'][0]['embedding'][:10]))
返回的embedding类型为:embedding_listembedding长度为:384embedding(前10)为:[0.060567744076251984, 0.020958080887794495, 0.053234219551086426, 0.02243831567466259, -0.024505289271473885, -0.09820500761270523, 0.04375714063644409, -0.009092536754906178, -0.020122773945331573, 0.015808865427970886]
三、使用讯飞星火API
尚未开放
四、使用智谱API
智谱有封装好的SDK,我们调用即可。
from zhipuai import ZhipuAIdef zhipu_embedding(text: str):api_key = os.environ['ZHIPUAI_API_KEY']client = ZhipuAI(api_key=api_key)response = client.embeddings.create(model="embedding-2",input=text,)return responsetext = '要生成 embedding 的输入文本,字符串形式。'response = zhipu_embedding(text=text)
response为zhipuai.types.embeddings.EmbeddingsResponded类型,我们可以调用object、data、model、usage来查看response的embedding类型、embedding、embedding model及使用情况。
print(f'response类型为:{type(response)}')print(f'embedding类型为:{response.object}')print(f'生成embedding的model为:{response.model}')print(f'生成的embedding长度为:{len(response.data[0].embedding)}')print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
response类型为:<class 'zhipuai.types.embeddings.EmbeddingsResponded'>embedding类型为:list生成embedding的model为:embedding-2生成的embedding长度为:1024embedding(前10)为: [0.017892399802803993, 0.0644201710820198, -0.009342825971543789, 0.02707476168870926, 0.004067837726324797, -0.05597858875989914, -0.04223804175853729, -0.03003198653459549, -0.016357755288481712, 0.06777040660381317]
本文对应源代码在此处,如需复现可下载运行源代码。
